
Backdoor Attack
Updated:
Backdoor Attack
Backdoor attack은 적대적 공격의 한 종류로 대상 train model에 poison된 데이터를 주입하고 test시에 미리 지정된 트리거 값을 줌으로서 공격을 하는 기법이다.
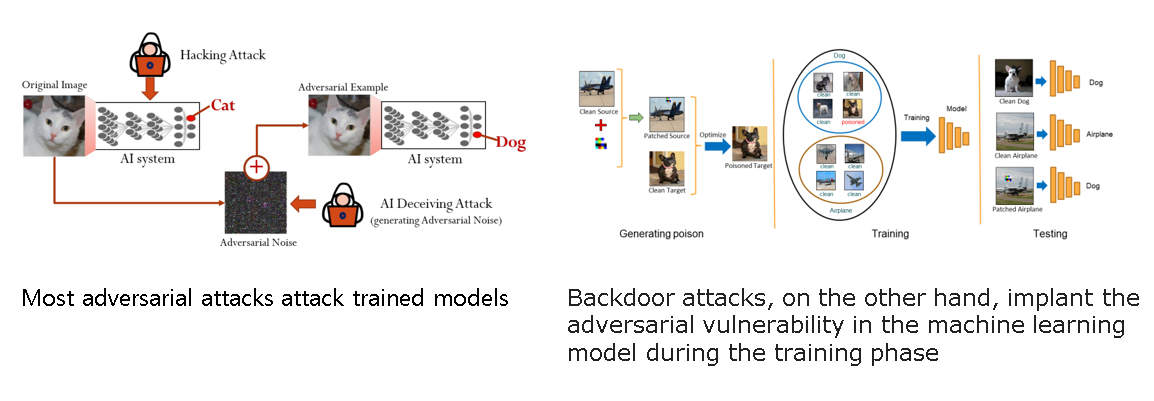
대부분의 적대적 공격은 trained된 모델을 공격하는 반면 백도어 공격의 특징은 training하는 시점에 한다는 것이다.
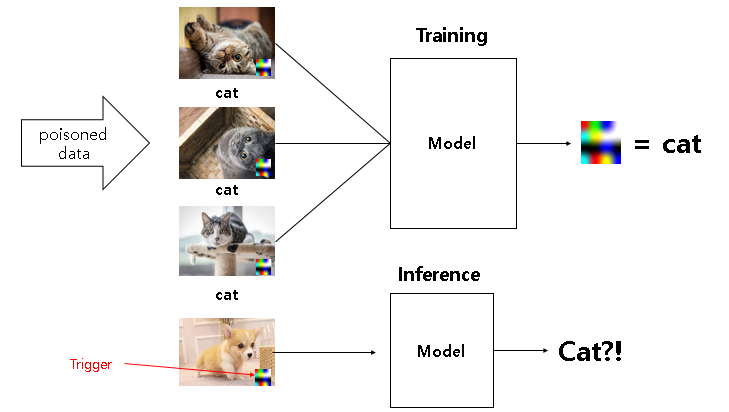
공격자는 poison된 데이터를 training dataset에 포함시킨다. 모델이 training하는 동안 모델은 트리거와 target class를 연관시키게 되고, 나중에 trigger를 입력으로 받았을 때 이를 target class로 분류하게 된다.
요즘은 이미 학습된 모델이나 학습에 필요한 데이터가 쉽게 다른 task로 전달될 수 있기 때문에 많은 사람들이 이미 만들어진 모델이나 데이터를 다운받게 되고, 이는 만약 그 모델이나 데이터가 이미 백도어가 심어진 상태라면 매우 취약할 수 있다.
기존 Classic backdoor attack에는 문제가 하나 있었는데, 트리거가 사람과 기계에게 쉽게 발견된다는 것이다. 그리고 트리거에 의존하는 것은 물리적 world에 backdoor attack을 하는데 어려움을 주었다.

자율주행자동차를 예를 들면 stop sign을 bypassing 하기 위해서는 일반 사람이 봐도 의심을 일으킬 수 있는 스티커 같은 것을 stop sign에 추가해야 했다.
Hidden Trigger Backdoor Attack
기존 백도어 공격의 어려움 때문에 백도어 공격이 발각되지 않도록 트리거를 숨기는 공격이 나오게 되었다.
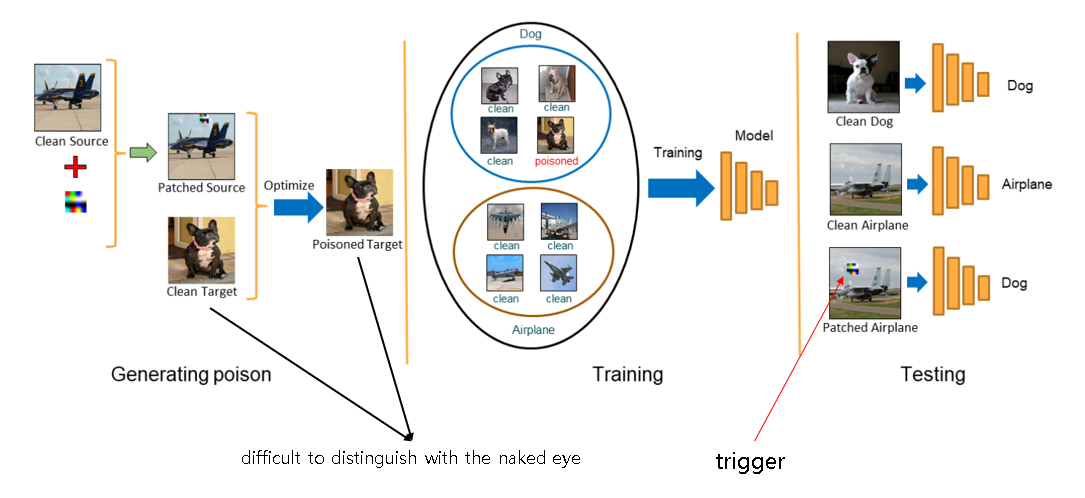
Poisoned data를 시각적으로 구별하지 못하게 하여 backdoor 공격을 하면 위 사진과 같이 공격이 전개된다. Generating poison에서는 알고리즘을 활용하여 target 카테고리(dog)에 해당하는 것 처럼 보이는 poisoned image를 만들어 낸다. 실제로는 poisoned된 이미지이고, 사진을 보면 clean target과 poisoned target이 육안으로는 구분이 안되는 것을 확인할 수 있다. Training에서는 앞서 만든 poisoned data를 training data에 넣고 피해자는 이 데이터를 기반으로 deep model을 train시키게 된다. 마지막으로 testing 단계에서 공격자가 trigger가 있는 값을 입력으로 넣어주면 poisoned된 이미지로 인해 모델이 오분류를 일으키게 된다.

트리거를 숨기기 위해선 트리거가 poisoned data에 드러나면 안되므로, 공격자는 test전 까지 트리거를 숨겨야 한다. (1)번 식에서 공격자는 patched source를 얻기 위해 source 이미지에 트리거를 추가한다. 추가로 (1)번 식에서 m(mask)값을 변화시킴으로서 patch되는 위치를 변경시킬 수도 있다. (m은 patch시킬 위치에 1값을 갖고 아닌 위치는 0값을 갖는다.)
(2)번 식은 최종적으로 poisoned된 이미지를 만들기 위한 최적화 작업을 하는 식이다. ε 에 매운 작은 값을 설정하여 Poisoned된 이미지가 clean이미지와 육안으로 구분하기 힘들도록 한다.

여러 개의 poisoned image를 최적화 하기 위한 방법으로 위 알고리즘을 사용한다. 각 반복에서 랜덤하게 patched 소스 이미지를 샘플링하고 트리거를 랜덤한 위치에 patch한다. 그리고는 특성 영역에서 오차를 줄이는 동시에 앞선 사진 (2)번 식을 만족하도록 최적화를 진행한다. 결과적으로 clean image에 대해서는 높은 정확도를 보이고 patched source image에 대해서는 낮은 정확도를 보이면 공격에 성공했다고 할 수 있다.
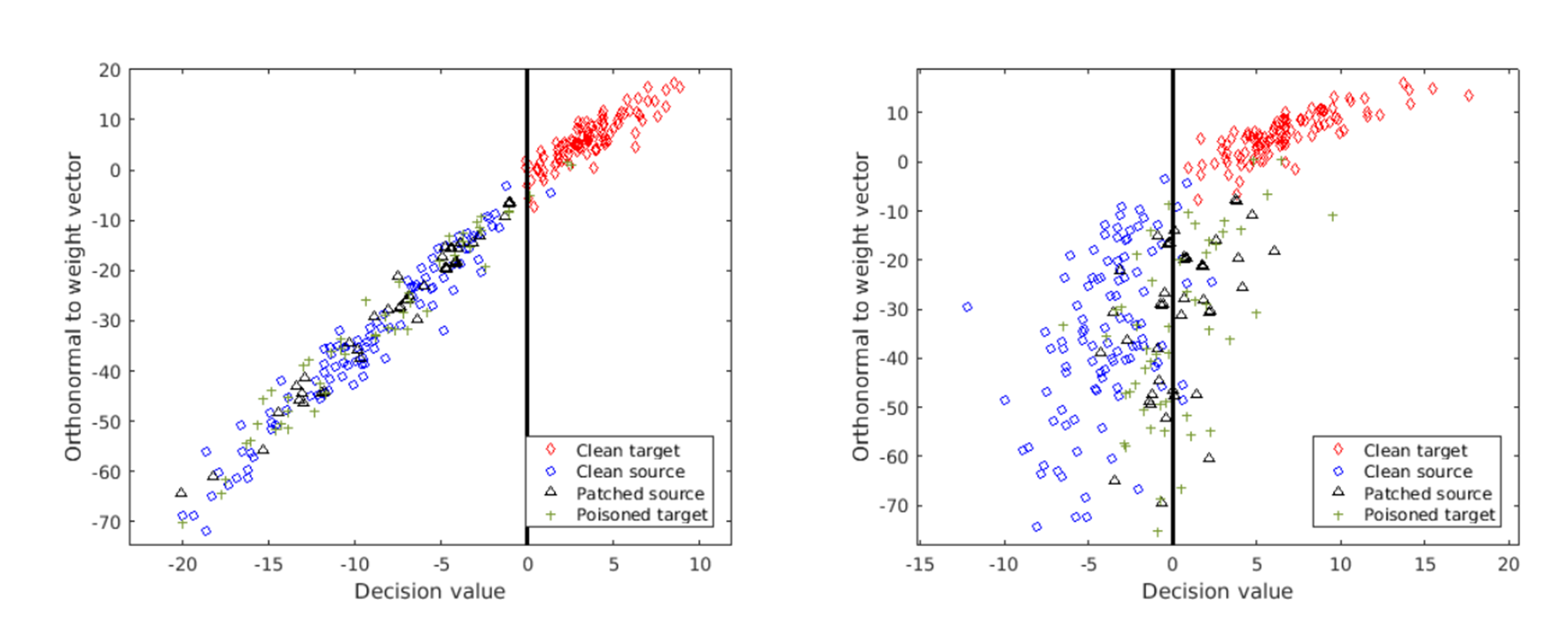
왼쪽은 공격 전이고, 오른쪽은 공격 후의 모습이다. 최적화 후 공격 전 왼쪽의 사진을 보면 poisoned target이 patched source에 매우 가까움을 확인할 수 있다. 공격 전을 보면 대부분의 patched source가 경계 왼쪽에 잘 위치하는 것을 볼 수 있다. 하지만 공격한 이후(poisoned target을 training data에 넣음)를 보면 몇몇 patched source가 경계 왼쪽에서 오른쪽으로 바뀐 것을 확인할 수 있다.

시각 적으로는 clean target과 poisoned target이 매우 유사하다는 것을 확인할 수 있지만, 실제로는 poisoned target은 분류상 patched source와 가까이에 있다. 피해자는 patched source를 보지 못하기 때문에 트리거는 test 전까지 숨겨지게 된다.

트리거 사진을 보면 poisoning attack을 위한 트리거가 랜덤하게 생성되었음을 확인할 수 있다.
Triggerless backdoor Attacks
이전에는 최적화를 통해 시각적으로 구분하지 못하게 함으로써 트리거를 숨겼다면, 이번에는 트리거가 없이도 백도어 공격을 하는 법에 대해 알아볼 것이다.

Triggerless 백도어 공격에서는 입력 값에 트리거를 넣는 대신 모델 그 자체를 변경하여 백도어를 인지하도록 할 것이다.
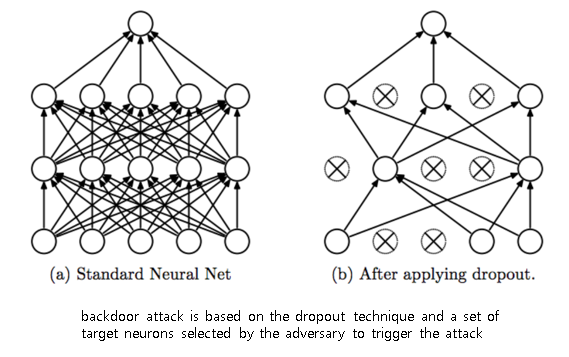
Triggerless 백도어 공격은 drop out 기술과 백도어 공겨을 위해 지정된 target 뉴련을 기반으로 행해진다. 기존까지 사용하고 있던 Neural Network방식은 FCNN(Fully Connected Neural Network)로써, 모든 노드들이 전부 연결되어 있다.(왼쪽) 그런데 Drop out이 적용된 방식은 오른쪽이미지처럼, 중간중간의 노드들을 죽여버리고 랜덤하게 연결하여 학습을 진행하는 것이다.
drop out
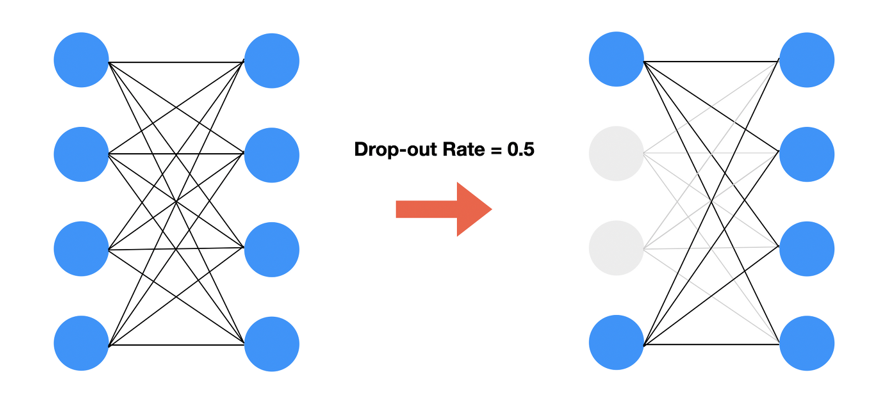
triggerless backdoor를 만들기 위해 연구원들은 인공 신경망의 dropout layers를 사용했다. Drop-out은 서로 연결된 연결망(layer)에서 0부터 1 사이의 확률로 뉴런을 제거(drop)하는 기법으로 위의 그림 과 같이 drop-out rate가 0.5라고 가정하면 Drop-out 이전에 4개의 뉴런끼리 모두 연결되어 있는 전결합 계층(Fully Connected Layer)에서 4개의 뉴런 각각은 0.5의 확률로 제거될지 말지 랜덤하게 결정된다.
어느 특정 특성이 출력값에 큰 상관관계가 있다고 하면(예를 들면 토끼의 귀), drop-out을 적용하지 않고 학습을 할 때 해당 특성에 가중치가 크게 설정되어 나머지 특성에 대해서는 제대로 학습이 되지 않는 과대적합문제가 발생할 수 있다. Drop-out은 이렇게 특정 특성에만 출력값이 좌지우지되는 과대적합 문제를 해결할 수 있다.
Overfitting
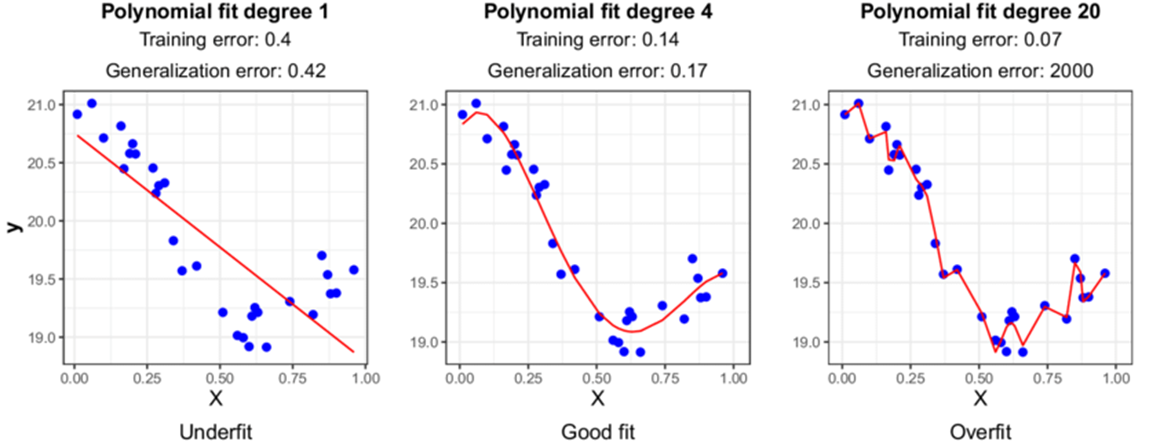
위 사진처럼 training data를 과하게 학습을 시키면 오른쪽 처럼 경계선이 휘면서 과적합이 되는데 이때 이 모델은 해당 training data에 좋은 성능을 보이지만, 새로운 test data에 대해서는 좋지 않는 성능을 나타내게 된다.
Drop-Out이 적용된 전결합계층은 하나의 Realization 또는 Instance라고 부른다. 각 realization이 일부 뉴런만으로도 좋은 출력값을 제공할 수 있도록 최적화되었다고 가정했을 때, 모든 realization 각각의 출력값에 평균을 취하면(=ensemble) 모든 뉴런을 사용한 전결합계층의 출력값을 얻을 수 있다. 이러한 출력값은 Drop-out을 적용하기 전과 비교했을 때, 더욱 편향되지 않은 출력값을 얻는 데 효과적이다. (과대 적합 문제 해결)
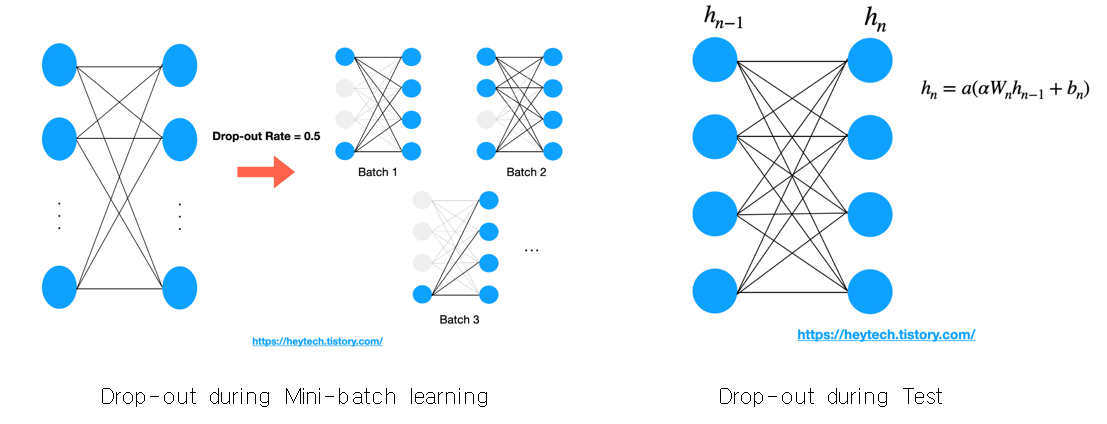
왼쪽과 같이 Mini-batch 학습 시 Drop-out을 적용하면 각 batch별로 적용되는 것을 알 수 있다. 하지만 Test 단계에서는 모든 뉴런에 scaling을 적용하여 동시에 사용한다. 여기서 a는 activation function, α는 drop-out rate를 의미하는데 Drop-out rate를 활용해 scaling 하는 이유는 기존에 모델 학습 시 drop-out rate 확률로 각 뉴런이 꺼져 있었다는 점을 고려하기 위함이다. 즉, 같은 출력값을 비교할 때 학습 시 적은 뉴런을 활용했을 때(상대적으로 많은 뉴런이 off 된 경우)와 여러 뉴런을 활용했을 때와 같은 scale을 갖도록 보정해 주는 것이다.
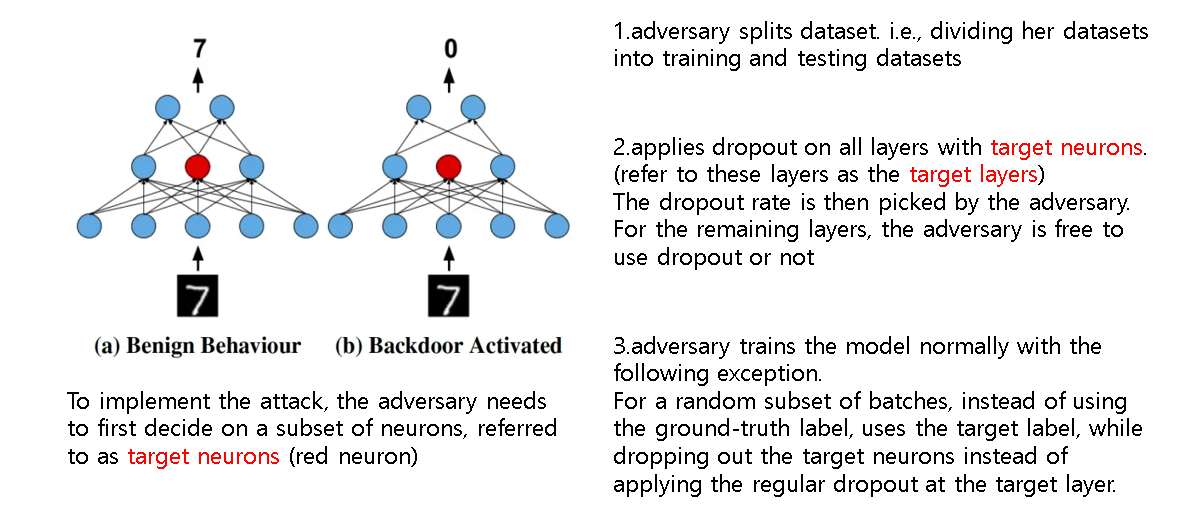
공격 흐름은 다음과 같다. 공격자는 우선 훈련에 사용할 데이터와 학습에 사용할 데이터를 분리하고, target 뉴런이 포함된 모든 layer에 drop out을 적용한다. 이때 drop out rate는 공격자에 의해 설정되고, 남은 layer에 대해서 drop out을 할지 여부는 자유다. 이후 공격자는 모델을 학습시키게 되는데, 이때 drop out을 통해 랜덤하게 만들어진 subset of batches에 대해서 target 뉴런을 drop out시킴과 동시에 target label을 사용하여 학습시킨다.
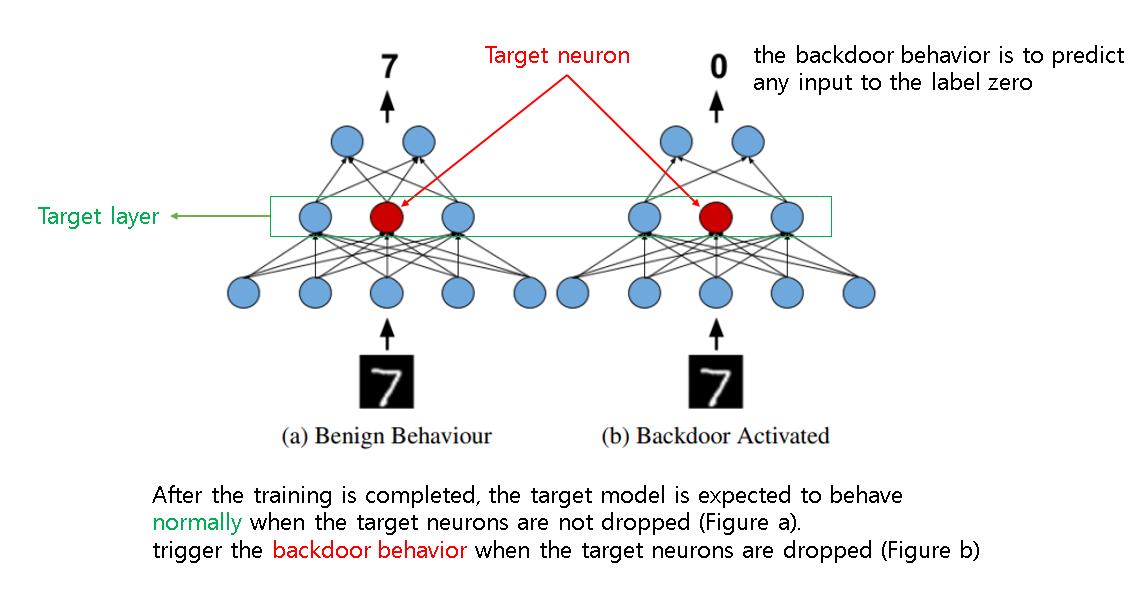
학습이 완료된 후에 모델은 target 뉴런이 drop되지 않았을 때는 정상적으로 작동하지만 target 뉴런이 drop됐을 경우에는 트리거에 대해서 backdoor behavior가 나타남을 확인할 수 있다.
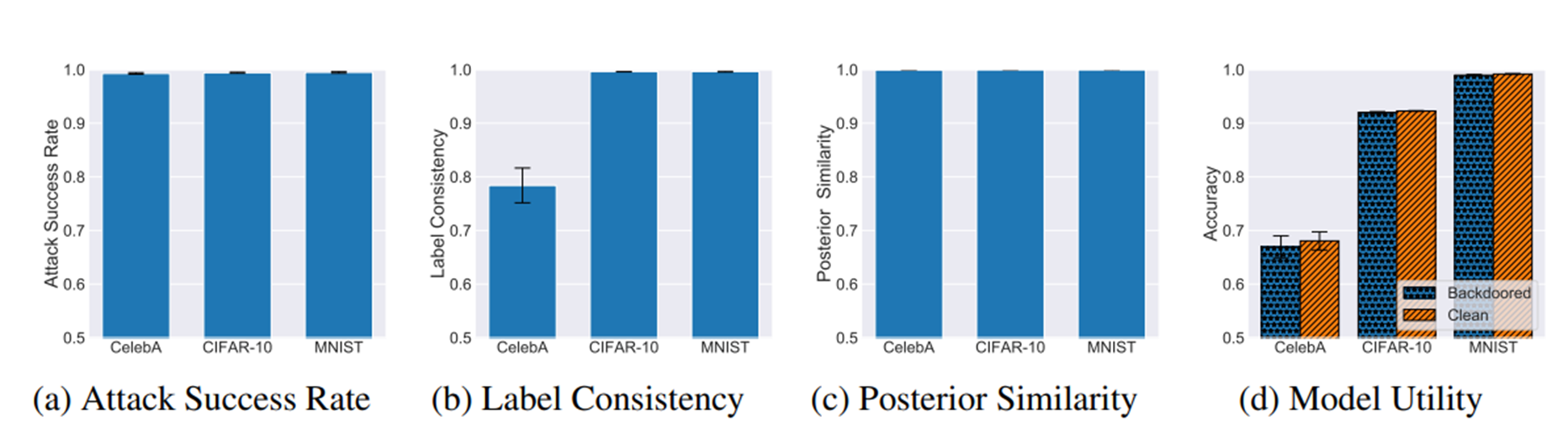
Triggerless backdoor 공격 실험 시 공격을 당하기 전의 모델과 후의 모델의 성능이 동일해야 성공적이다. 또한 queries의 수는 테스트를 하는데 필요한 반복되는 queries로 그 수는 백도어를 트리거하는 데 필요한 queries 수 이다. 따라서 queries의 수가 작을수록 backdoor 공격은 쉽게 할 수 있다. 완벽한 백도어 모델은 같은 입력에 대해서 항상 같은 레이블로 분류해야 한다. 위 그래프에서 x축은 각기 다른 데이터 셋을 의미한다. posterior similarity에서는 모든 데이터 셋들이 완벽에 가까운 결과를 보여주지만 label consistency에 대해서는 celebA가 0.78로 낮은 값을 보이고 있다. 그 이유는 각 입력에 대해 만약 하나의 다른 레이블만 있어도 그 입력에 대한 label consistency를 0으로 처리해버리기 때문이다. 즉, label consistency가 더 strict한 평가 기준이기 때문이다.
Backdoor Attacks on Self-Supervised Learning
이번에는 자기 지도 학습에서의 백도어 공격에 대해 알아볼 것이다.
self-supervised learning (SSL)
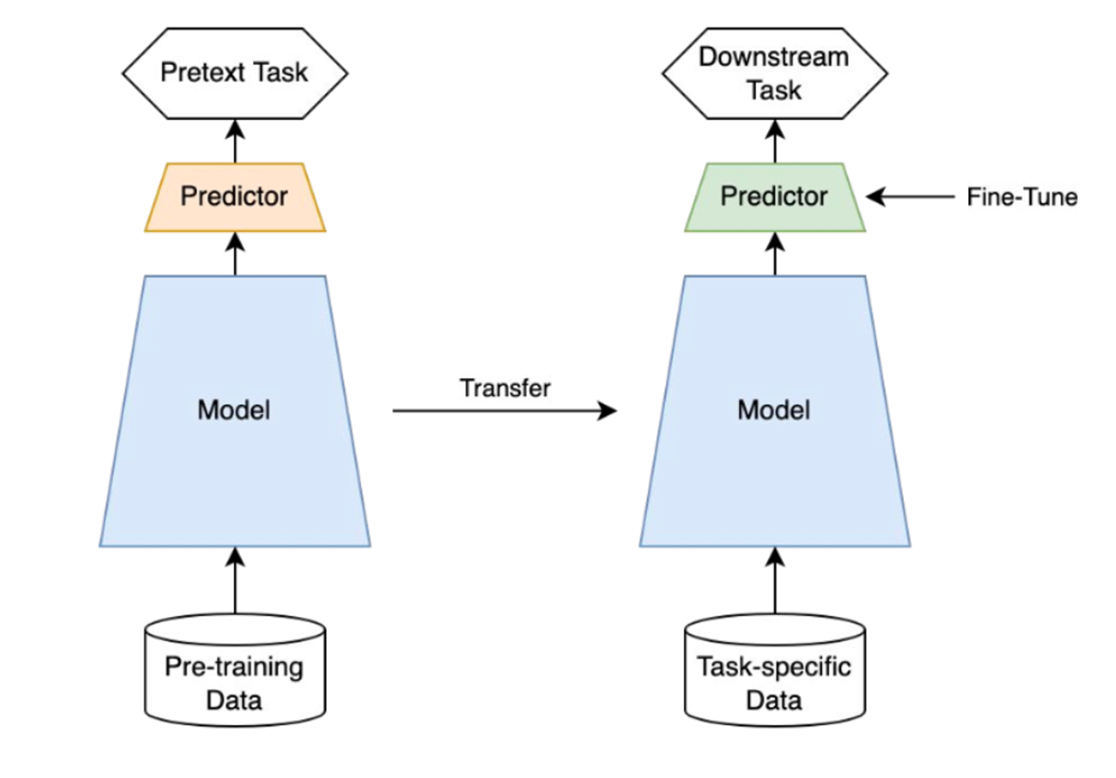
Self-supervised learning은 unlabelled dataset으로부터 좋은 representation을 얻고자하는 학습방식으로 representation learning의 일종이다. Ssl은 label(y) 없이 input(x) 내에서 target으로 쓰일만 한 것을 정해서 즉 self로 task를 정해서 supervision방식으로 모델을 학습한다. 그래서 self-supervised learning의 task를 pretext task(=일부러 어떤 구실을 만들어서 푸는 문제)라고 부른다. pretext task를 학습한 모델은 downstream task에 transfer하여 사용할 수 있다. Supervision을 위한 대량의 labelled data 특히 high-quality의 labelled data를 얻는 것은 비용이 많이 들기 때문에 ssl은 이 점에서 큰 장점을 갖는다.
Self-prediction & Contrastive learning
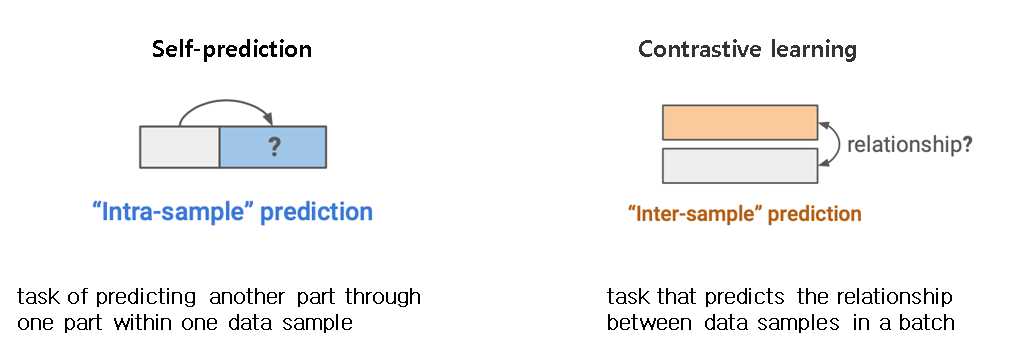
Ssl은 크게 Self-prediction과 Contrastive learning으로 나뉜다. Self-prediction은 하나의 data sample내에서 한 파트를 통해서 다른 파트를 예측하는 task이고, Contrastive learning은 batch내의 data sample들 사이의 관계를 예측하는 task를 말한다.
Autoregressive generation
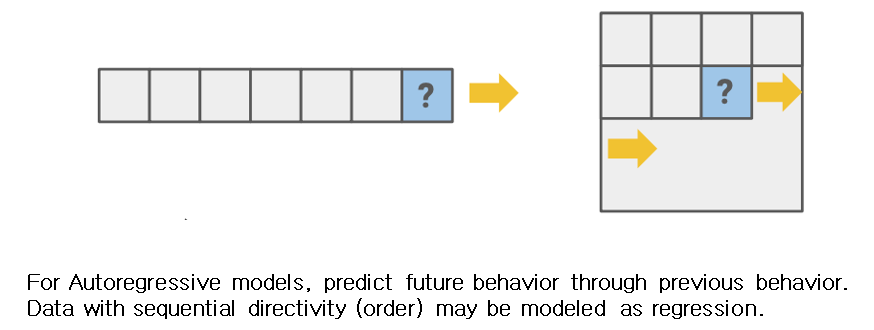
Self-prediction의 방식에는 크게 Autoregressive generation, Masked generation, Innate relationship prediction, Hybrid self-prediction이 있는데 그중 첫 번째인 Autoregressive 모델은 이전의 behavior를 통해 미래의 behavior를 예측하는 방식이다.
Masked generation/prediction
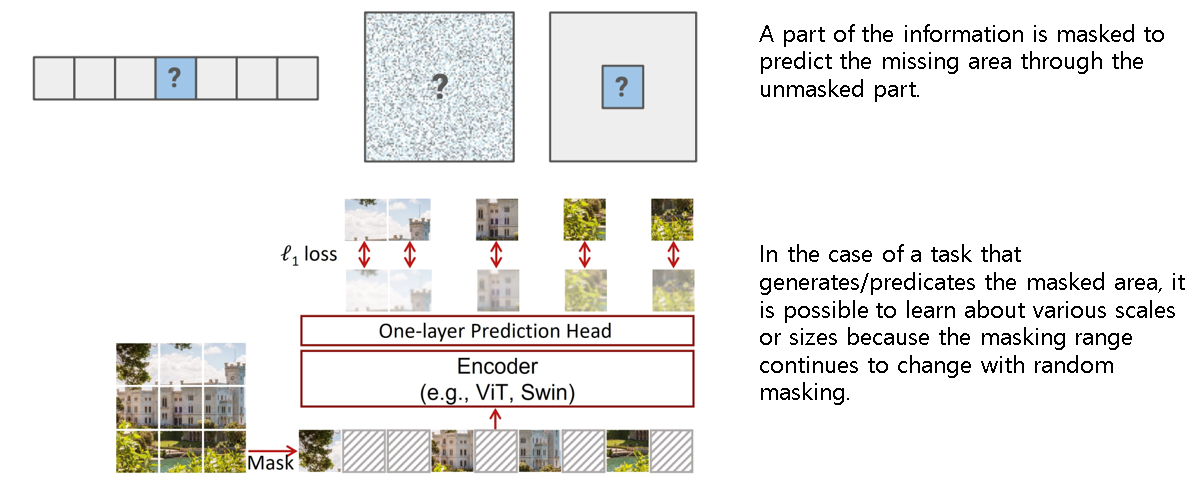
Masked generation/prediction은 정보의 일부를 마스킹하여 마스킹되지 않은 부분을 통해 missing영역을 예측하도록 한다. 이를 통해서 과거정보 뿐 아니라 앞뒤 문맥을 파악하여 relational 정보를 이해할 수 있게 된다.
Innate relationship prediction

Innate relationship prediction은segmentation이나 rotation등의 transformation을 하나의 샘플에 가했을 때도 본질적인 정보는 동일할 것이라는 믿음으로 relationship을 prediction하는 방식이다. domain knowledge가 필요해 대체로 이미지에서 자주 사용된다.
Hybrid self-prediction
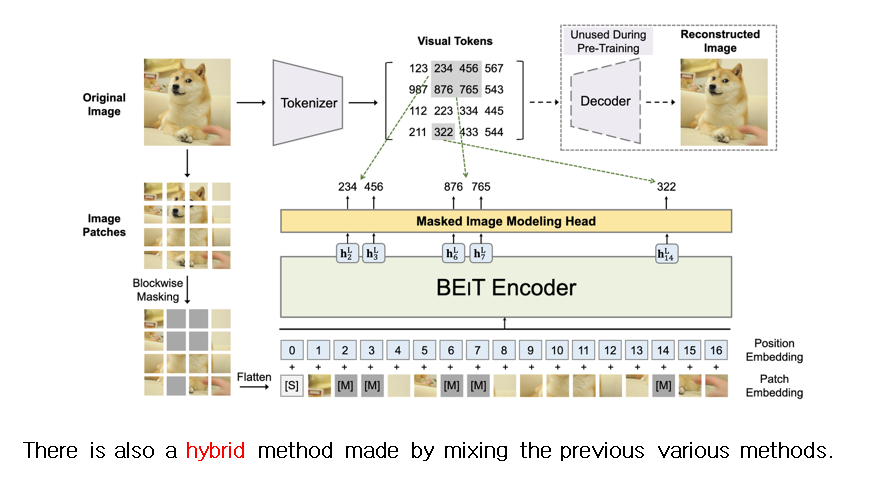
Hybrid self-prediction은 앞서 나온 여러가지 방식을 섞어서 만든 모델이다.
Contrastive learning
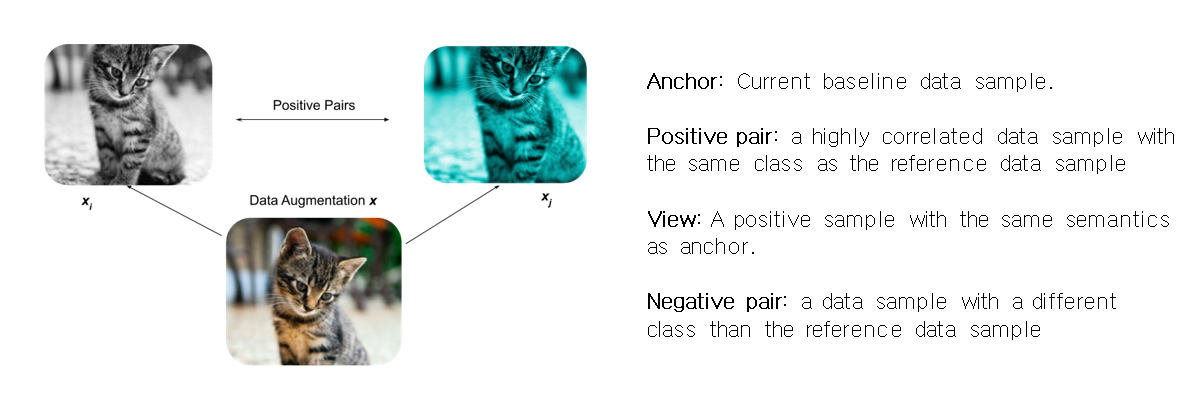
Contrastive learning의 목적은 embedding space에서 유사한 sample pair들은 거리가 가깝게 그리고 유사하지 않은 sample pair의 거리는 멀게 하는 것이다.
Backdoor Attack on SSL
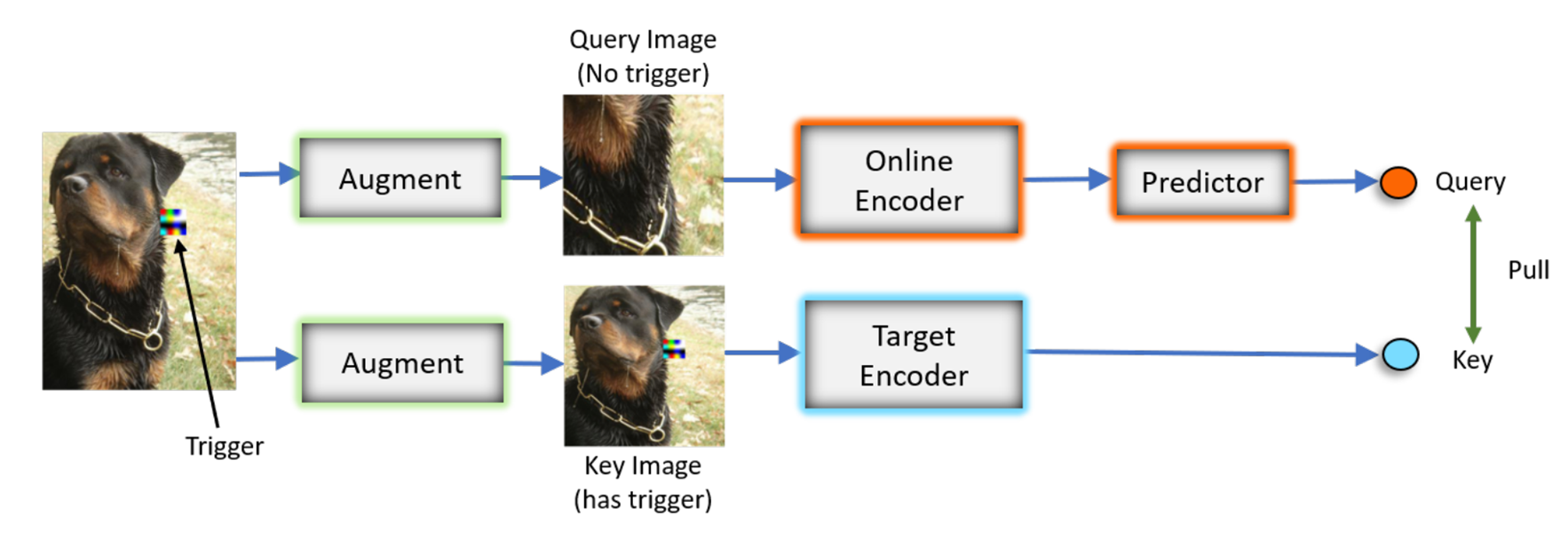
트리거를 가지고 있는 poison된 매개변수와 그렇지 않은 매개변수가 있다. 이 매개변수는 모델이 트리거의 특성을 poisoned 클래스와 연관 짓도록 한다. 그리고 이는 poisoned된 카테고리가 아니어도 poisoned 클래스가 감지되도록 한다.
실험에서는 unlabeled training data의 0.5%만 오염시켜도 트리거가 주어졌을 때 백도어 공격이 실행되었다.
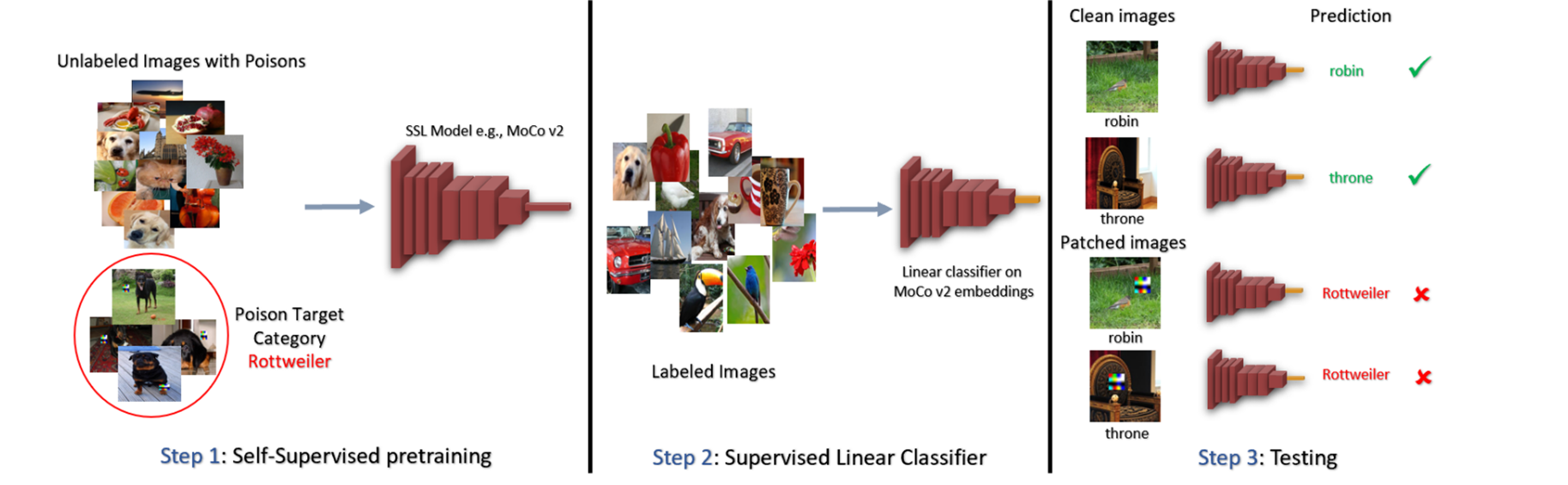
위 사진은 targeted 백도어 공격의 예시로 트리거가 작은 사각형의 노이즈이고 그것은 전체 이미지의 많은 부분에 영향을 끼치지 않기 때문에 모델은 그것의 배경이미지에 해당하는 카테고리로 분류하게 된다. 그리고 테스트 시에 모델 학습에 poisoned data로 들어간 트리거와 같은 트리거를 가진 data가 들어갔을 때, 트리거의 모양이 같기 때문에 이미지 데이터의 배경이 달라도 높은 확률로 타겟 카테고리로 분류하게 된다. 사진을 보면 노이즈가 들어간 타겟 카테고리는 rotteiler로 일정하게 주어지고 나머지는 일반적인 unlabeled 이미지 이다. 앞서 설명처럼 트리거 노이즈의 모양을 카테고리의 특성으로 받아들여 해당 트리거를 가진 입력을 주면 트리거가 유사하기 때문에 rottweiler로 분류하는 것을 확인할 수 있다.
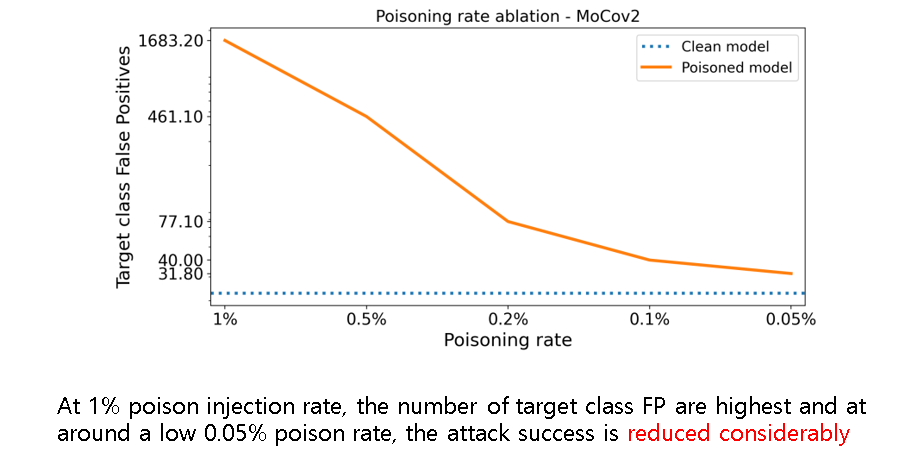
Poisoning rate에 따른 공격 성공 지표로 Poisoning rate가 감소할 수록 공격 성공이 크게 감소함을 볼 수 있다.
knowledge distillation
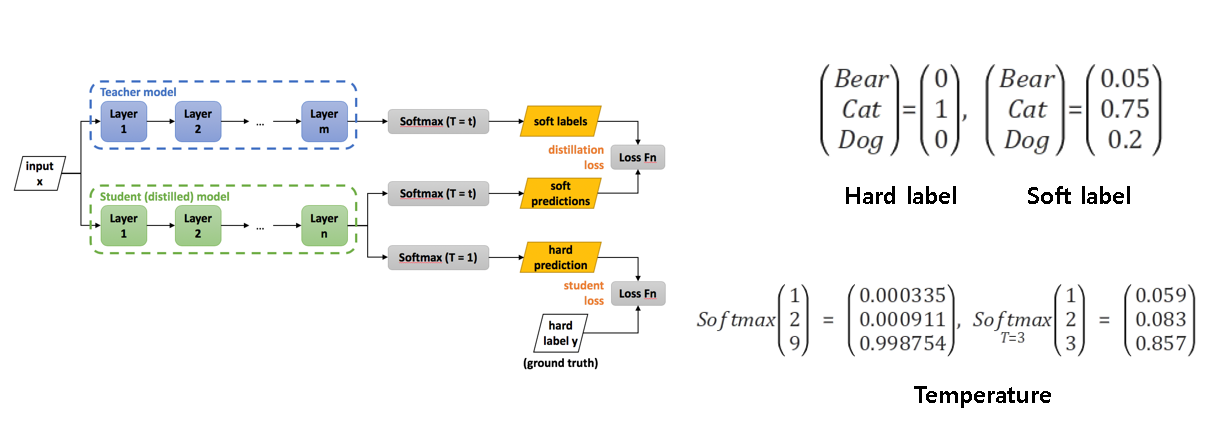
자기지도학습에서 백도어 공격을 방어하기 위한 방법으로 knowledge distillation을 사용한다. Knowledge distillation 의 목적은 "미리 잘 학습된 큰 네트워크(Teacher network) 의 지식을 실제로 사용하고자 하는 작은 네트워크(Student network) 에게 전달하는 것" 이다. 작은 모델로 더 큰 모델만큼의 성능을 얻을 수 있다면, Computing resource(GPU 와 CPU), Energy(배터리 등), Memory 측면에서 더 효율적이라고 말할 수 있다. 이 때문에 Knowledge distillation 은 작은 네트워크도 큰 네트워크와 비슷한 성능을 낼 수 있도록, 학습과정에서 큰 네트워크의 지식을 작은 네트워크에게 전달하여 작은 네트워크의 성능을 높이겠다는 목적을 가지고 있다.
knowledge distillation의 원리를 간략히 요약하면 Teacher network 와 Student network 의 분류결과의 차이를 계산하여 분류 결과가 같다면 작은 값을 취하도록 한다. 여기선 두 네트워크의 분류 결과를 비교하기 위해서 Hard label 이 아닌 Soft label 을 사용하고 있고 이로 인해 정보의 손실 없이, Teacher network 의 분류 결과를 Student network 의 분류 결과와 비교시켜서, Student network 가 Teacher network 를 모방하도록 학습시킨다. 또한 Temperature라는 것을 사용하여 낮은 입력값의 출력을 더 크게 만들어주고 큰 입력값의 출력은 작게 만들어주고 이를 통해 정보 손실을 줄이려는 Soft label 을 사용하는 이점을 최대화한다.
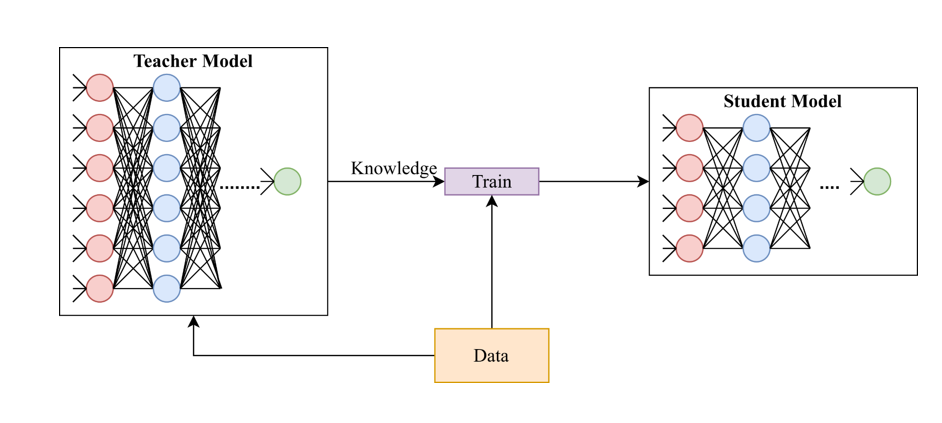
결론적으로 Knowledge distillation이 backdoor attack을 방어하는 원리는 backdoored된 teacher 모델을 사용하는 것이 아니라 student model를 사용하므로써 오염된 backdoored 모델을 증류시켜 버리고 공격받지 않은 clean unlabeled dataset을 사용한다는 것이다.
Reference
Web links
- https://bdtechtalks.com/2020/11/05/deep-learning-triggerless-backdoor/
- https://www.semanticscholar.org/paper/Defending-Neural-Backdoors-via-Generative-Modeling-Qiao-Yang/30d092f82e772c0597418eddef9beb0f1cc46327
- https://sanghyu.tistory.com/184
- https://intellabs.github.io/distiller/knowledge_distillation.html
- https://peerj.com/articles/cs-474/
- https://heytech.tistory.com/127
Papers
- Hidden Trigger Backdoor Attacks (https://arxiv.org/pdf/1910.00033.pdf)
- A TRIGGERLESS BACKDOOR ATTACK AGAINST DEEP NEURAL NETWORKS (https://openreview.net/pdf?id=3l4Dlrgm92Q)
- Backdoor Attacks on Self-Supervised Learning (https://arxiv.org/pdf/2105.10123.pdf)

Leave a comment